- Published on
Building an Autocomplete Library for ANTLR4 Part 3 - Rules
In the last post we've seen several types of transitions within the nodes of a rule. Now it's time to talk about what happens when you enter or exit one. ANTLR4's VSCode extension represents rules in the ATN as as a "weird and magical" state that somehow gets called. But how do they work exactly?
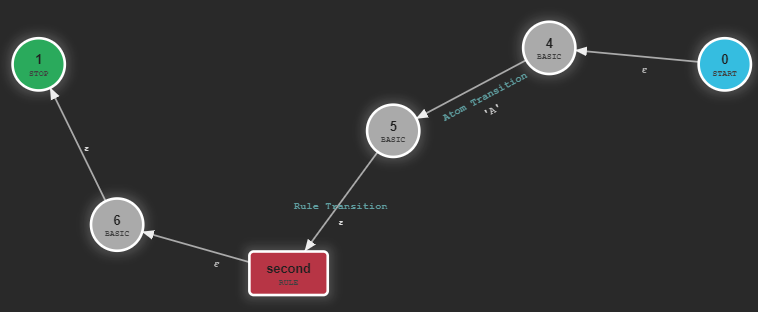
This is just a visual representation to show the ATN of only one rule. In reality it isn't that different from the other types of transitions. Imagine a grammar:
first: 'A' second;
second: 'B';
A more accurate picture of the whole ATN would be:
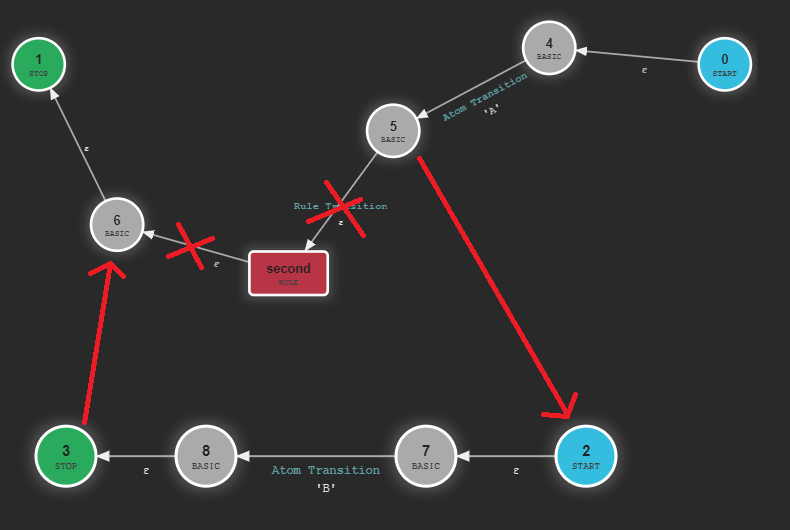
To enter a rule the ATN just moves to the initial state of that rule. And when it finishes it the RuleStopState points back to the caller. But how does it
know who's the caller? Well... it doesn't. The ATN doesn't have a call stack (though the machine that executes it does). Instead the last transition of a rule points to every possible caller.
That's why using the autocompleter as it is right now leads to unexpected results:
await givenGrammar(`
first: called 'A';
second: called 'B';
third: called 'C';
called: 'F';`)
.whenInput("F").thenExpect(["A", "B", "C"]);
This is wrong. The starting rule is first, so it should only return "A".
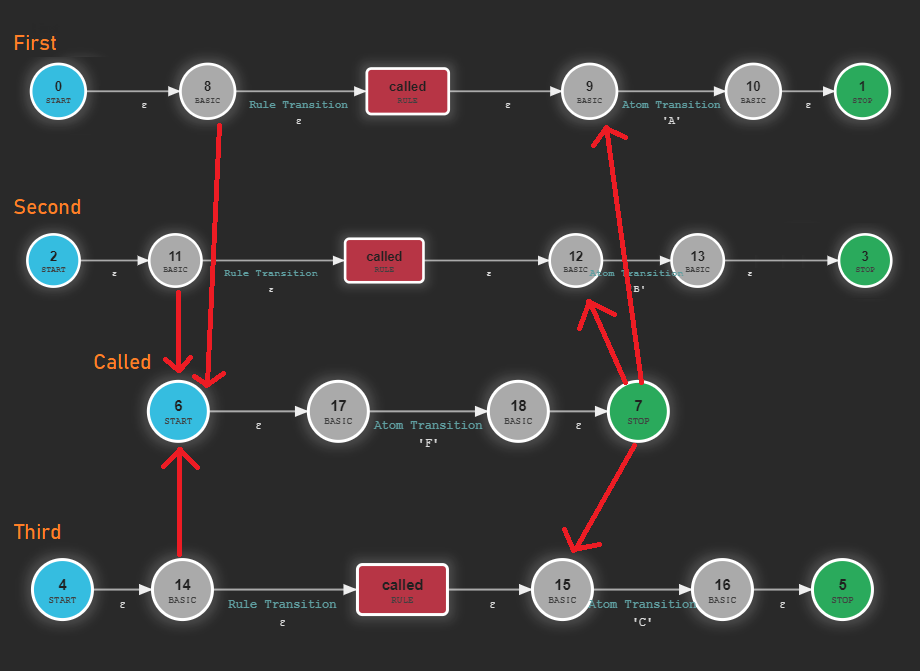
So how does ANTLR4 know which transition is the correct one? Are we doomed? Actually, there's a way of knowing.
But it's not in the RuleStopState, instead it's in a special type of transition: RuleTransition. These are the transitions that go from
the callee to the called rule. They are epsilon transitions, so they don't consume input, but they have a special attribute followState that, as the name implies, points to the state the machine has
to follow after the rule ends.
It also includes the precedence of the rules, but I'll go to that later. Now let's focus on fixing the previous test.
Fixing the rules
The idea is that when the machine enters a rule we need to store the followState, and when it exits it we need to limit the machine so it can only
go through the correct transition. And since we can enter an undetermined amount of rules, we need to store this information in a stack that I'll
call the parserStack.
As far as I know the ATN should never try to exit a rule that isn't at the head of the stack, but better safe than sorry. Plus, adding the rule to the stack has an additional advantage: It allows us to know the context in which a suggestion was made. More on that later.
The stack will contain pairs [<ruleIndex>, <followState>]. In order to do this I'm going to add the initial rule to the stack, pointing to a Symbol STOP.
const STOP = Symbol("Stop");
autocomplete(input) {
// ...
const stack = [[0, initialState, [], [[startingRule, STOP]]]];
return process(tokenList, stack);
}
Why STOP instead of null? Because I'm going to define a variable limitNextState that determines if the machine is restricted to a certain transition. And it needs to distinguish between three cases
- The machine isn't restricted because it's not exiting a rule:
limitNextState === null - The machine just finished the top rule and MUST STOP:
limitNextState === STOP.- The initial rule works just as the others, so if there are multiple references to it the last state will have transitions to multiple states. Without
differenciating between
STOPandnull, the machine would never stop (until it runs out of input or fails). - Yes, this is a corner case and most grammars probably don't call the starting rule
- The initial rule works just as the others, so if there are multiple references to it the last state will have transitions to multiple states. Without
differenciating between
- The machine just finished a rule and is exiting it
limitNextState === indexOfSomeState
function process(tokens, stack) {
const suggestions = [];
while(stack.length !== 0) {
const [tokenStreamIndex, state, alreadyPassed, parserStack] = stack.pop();
let limitNextState = null;
// The last state of a rule is always a `RuleStopState`
// - In theory 'parserStack.length' should never be 0
if (state instanceof RuleStopState && parserStack.length !== 0) {
const [lastRule, nextState] = parserStack[parserStack.length-1];
// Again, in theory this should never happen
if (!state.ruleIndex === lastRule)
throw new Error("Unexpected situation. Exited a rule that isn't the last one that was entered");
limitNextState = nextState;
// It's important to make a shallow copy to avoid affecting the other alternatives.
parserStack = parserStack.slice(0,-1);
}
A small but important detail is that parserStack should be inmutable. The autocompleter tries all paths, and it doesn't modify nor clone the stack
when it traverses a non-epsilon transition. This means two paths could share the same stack and musn't modify it to avoid affecting the other path.
That's why I used parserStack.slice(0,-1); instead of .pop().
Now, when it sees an epsilon transition it needs to cover two cases:
- It's a rule transition. In this case it traverses the transition as usual but adds the rule to the
parserStack:
for (let i = state.transitions.length - 1; i >= 0; i--) {
const it = state.transitions[i];
if (it.isEpsilon && !alreadyPassed.includes(it.target.stateNumber)) {
const newParserStack = it instanceof RuleTransition ? [...parserStack, [it.ruleIndex, it.followState]] : parserStack;
- If it's not but the state is limited, check whether this transition goes to the expected state:
if (limitNextState && it.target !== limitNextState) continue;
(This could go right after the const it, but the only case in which limitNextState isn't null is in a RuleStopState which is an epsilon transition)
And voilah! It works.
await givenGrammar(`
first: called 'A';
second: called 'B';
third: called 'C';
called: 'F';
`).whenInput("F").thenExpect(["A"]);
Of course, you need to remember to pass the parserStack every time you want to traverse a new transition:
//Epsilon transitions
stack.push([tokenStreamIndex, it.target, [it.target.stateNumber, ...alreadyPassed], newParserStack]);
// Atom/SetTransition
} else if (it.label.contains(nextToken.type)) {
stack.push([tokenStreamIndex + 1,
it.target,
[],
parserStack // <------- This is new
]);
}
Adding the stack to the suggestions
As I mentioned previously, storing the parser stack allows us to know the context in which the machine makes a suggestion. This could be useful for making specific conditions: "If an identifier is inside an expression, suggest this, if it's inside a variable definition, suggest that".
To do this we need to make suggestions a bit more complex. Now instead of returning the token index, it'll return an object:
class Suggestion {
constructor(token, ctxt) {
this.token = token;
this.ctxt = ctxt; // Inside the suggestion I prefer to call it context instead of stack
}
}
Then I'll pass the stack to intervalToArray so that it directly returns a list of suggestions. But remember, the parserStack holds both the index of the rule
and the followState. We don't care about the latter, hence the .map(x => x[0])
suggestions.push(...intervalToArray(it.label, parserStack.map(x => x[0])));
//...
function intervalToArray(interval, stack) {
//...
values.push(new Suggestion(v, stack)); //This used to be values.push(v);
To test it, I made an extension to the testing utilities:
const base = givenGrammar(`
first: 'A' second fourth;
second: 'A' third;
third: A;
fourth: 'A';
A: 'A';
`);
await base.whenInput("").thenExpectWithContext([{s: "A", ctxt: [["first"]]}]);
await base.whenInput("A").thenExpectWithContext([{s: "A", ctxt: [["first", "second"]]}]);
await base.whenInput("AA").thenExpectWithContext([{s: "A", ctxt: [["first", "second", "third"]]}]);
For each suggestion s is the token and the ctxt is an array of contexts. Right now each token has a single context, but that is about to change.
Merging suggestions
Since we are already improving the overall interface of suggestions, it's a good time to handle something else: Avoiding duplicated suggestions.
For a grammar like:
const base2 = givenGrammar(`
first: 'A' (option1 | option2);
option1: B;
option2: B;
A: 'A';
B: 'B';
`);
Right now we would get something like
await base2.whenInput("A").thenExpectWithContext([{s: "B", ctxt: [["first", "option1"]]}, {s: "B", ctxt: [["first", "option2"]]}]);
But since both suggestions are the same token, the library could easily merge them into one and combine the contexts. The algorithm isn't really interesting so I'll ignore it to avoid bloating the post.
class BlogAutocompleter {
autocomplete(input) {
//...
const suggestions = process(tokenList, stack);
return groupSuggestions(suggestions);
And done. Now there's a single suggestion with two contexts:
await base2.whenInput("A").thenExpectWithContext([{s: "B", ctxt: [["first", "option1"], ["first", "option2"]]}]);
Precedence in rules
One of the things that caught my eye while I was studying antlr4-c3 was the precedence of rules. ANTLR4 handles left-recursion automatically by rewriting the rules and using precedence.
If you have:
expr: expr '*' expr
| expr '+' expr
| expr '(' expr ')' // f(x)
| id
;
it will rewrite it to:
expr[int pr] : id
( {4 >= $pr}? '*' expr[5]
| {3 >= $pr}? '+' expr[4]
| {2 >= $pr}? '(' expr[0] ')'
)*
;
Quoting the oficial ANTLR4 docs:
The predicates resolve ambiguities by comparing the precedence of the current operator against the precedence of the previous operator. An expansion of expr[pr] can match only those subexpressions whose precedence meets or exceeds pr.
By pure chance the autosuggester already works with this rules. But to be more specific, there are two reasons:
PrecedencePredicateTransitionare epsilon transitions, so the machine is already traversing them.- For suggestions it shouldn't really matter if it reads
3 + (4 * 2)or(3 + 4) * 2.
I wrote the second point with a lot of confidence, just to be crushed a few seconds later. Does precedence matter? I haven't found an example that fails,
but that doesn't mean there isn't one. antlr4-c3 takes precedence into account, and I definitely trust that Mike Lischke knows way more than me.
So let's add it. First we need to store the precedence. This works just as followState.
// Initial definition of the stack in 'autocomplete'
const stack = [[0, initialState, [], [[startingRule, STOP, 0]]]];
// We also add it to 'process'
const newParserStack = it instanceof RuleTransition ? [...parserStack, [it.ruleIndex, it.followState, it.precedence]] : parserStack;
And finally when we find a PrecedencePredicateTransition, check if the transition precedence is >= of the rule precedence. If NOT, skip it:
function process(tokens, stack, Parser) {
//...
for (let i = state.transitions.length - 1; i >= 0; i--) {
const it = state.transitions[i];
if (it.isEpsilon && !alreadyPassed.includes(it.target.stateNumber)) {
if (it instanceof PrecedencePredicateTransition && it.precedence < parserStack[parserStack.length - 1][2])
continue;
That's all. It wasn't that hard. I feel like I have spent more time finding an excuse to avoid implementing it than actually doing it.
Let's test it with an example that contains multiple operators:
const grammar = givenGrammar(`
expr: expr (MULT|DIV) expr
| expr (PLUS|MINUS) expr
| ID;
literal: ID;
WS: [\\p{White_Space}] -> skip;
ID: [a-zA-Z0-9]+;
MULT: '*';
DIV: '/';
PLUS: '+';
MINUS: '-';
`);
await grammar.whenInput("a + b * c + e * f / v").thenExpect(["MULT", "DIV", "PLUS", "MINUS"]);
Reseting the alreadyPassed in nestedRules
In the previous post we defined an array called alreadyPassed that contains a list of epsilon transitions that the ATN has already traversed. Otherwise the machine could get stuck in a loop, since these
transitions don't consume input. This get's a bit more convoluted with rules, specially with recursion.
I discovered this when I was testing the following grammar:
const leftRecursiveBase = givenGrammar(`
stat: expr '=' expr ';' // e.g., x=y; or x=f(x);
| expr ';' // e.g., f(x); or f(g(x));
;
expr: expr '*' expr
| expr '+' expr
| expr '(' expr ')' // f(x)
| id
;
id: ID;
ID: [a-zA-Z]+;
WS: [\\p{White_Space}] -> skip;
`);
await leftRecursiveBase.whenInput("aaa + bbbb").thenExpect(["*", "+", "(", "=", ";"])
This failed because the library didn't suggest = and ;. The reason? The machine was traversing the rule expr multiple times in a recursion, but the alreadyPassed array wasn't updated appropiately. So when the machine was about to traverse an epsilon transition it thought that it already had traverse
it when in reality it hadn't.
So I changed it so that when the machine enters or exits a rule it resets alreadyPassed.
if (it.isEpsilon && !alreadyPassed.includes(it.target.stateNumber)) {
//...
stack.push([tokenStreamIndex,
it.target,
it instanceof RuleTransition || state instanceof RuleStopState ? [] : [it.target.stateNumber, ...alreadyPassed],
newParserStack]);
With this simple change the above test worked perfectly.