- Published on
Building an Autocomplete Library for ANTLR4 Part 4 - Experimenting with error recovery
In the last two posts I explained how the autocompleter traverses rules and the most common transitions. I could go on with the remaining ones, but they aren't that compelling. Instead I'd rather talk about a little experiment I made: Adding rules for error recovery.
One of the problems of autocompletion is that if there's a syntax error in the middle of the text, the library will crash even if the cursor is much further away and there is way more than enough context to generate suggestions. Let's see a simple example:
let a = ;
let b = 3 // <- The cursor is right after the '3'
The fact that the first variable definition is incomplete doesn't affect the suggestions after the 3. There are ways to handle this, though
I haven't found any obvious or mainstream method. For example, you could allow errors in the grammar (and check for them in another validation step
later), thereby the ATN wouldn't fail.
Another way could be just looking at the previous tokens, for example if you see LET <ID> = you can guess it's a definition. Of course this is quite limited.
I suspect VSCode's IntelliSense does something like tokenizing the whole text and then suggesting every single token (plus more if it can fetch data from
imported files) changing the priority of the suggestions depending on the current context. But it's still a bit weird because a lot of suggestions
don't really fit, though honestly it's still quite practical.
And what really surprises me is that libraries like antlr4-c3 don't solve this either. So my first thought was: What if I could tell the ATN that it can
skip the let a = ; because it doesn't really matter for this situation. Or in other words, what if I could define rules for recovering from errors.
This won't be a perfect solution. Defining these rules correctly will require a bit of knowledge about the internals of the ATN, but it still has potential. Imagine that you have a grammar like this one:
expression: assignment | simpleExpression;
assignment: (VAR | LET) ID EQUAL simpleExpression;
simpleExpression
: simpleExpression (PLUS | MINUS) simpleExpression
| simpleExpression (MULTIPLY | DIVIDE) simpleExpression
| variableRef
| functionRef
;
variableRef: ID;
functionRef: ID OPEN_PAR CLOSE_PAR;
And you could tell it "If it fails while the machine is in the rule 'Assignment', and you find the token 'VAR', then go back to the beginning of the rule 'assignment':
{ifInRule: parser.RULE_assignment, andFindToken: parser.VAR, thenGoToRule: parser.RULE_assignment}
If the condition is triggered, it'll override the state of the machine. Of course this is dangerous and could lead to inconsistent states. This post is a bit of a proof of concept and I'm not sure if it could be simplified somehow to make it more usable. For now let's assume that the people that use this know what they are doing (cause I definitely don't).
What is failure?

In ancient greece, stoics defined failure as a state of being in which one's desires exceed their grasp, while Epicureans defined failure as... Okay, I'm joking with the answer, but not with the question.
Deciding when to trigger a recovery isn't as simple as it seems. The autocompleter searches the ATN exhaustively, meaning that it tries every single possible path and most of those paths fail. So, should it try to recover from each path? My first answer was YES!. And it did NOT go well.
The idea was something like this:
} else if (it instanceof AtomTransition || it instanceof SetTransition) {
if (nextToken === caret) {
suggestions.push(...intervalToArray(it.label, parserStack.map(x => x[0])));
} else if (it.label.contains(nextToken.type)) {
stack.push([tokenStreamIndex + 1,
it.target,
[],
parserStack
]);
} else
tryToRecover(); // <-----------
Imagine that tryToRecover checks if there is a rule that establishes how to recover and if there is, applies it. I'll talk about that later.
This worked but was extremely inefficient and slowed everything down too much. I had to find another solution.
Failure is not finding a suggestion
The autocompleter only has three possible outcomes:
- It finds at least one suggestion
- It ends well but doesn't find any suggestion
- It fails
In most grammars the second option is impossible. They usually end with an EOF, which ensures that ANTLR4 parses the whole text. If that's
the case it will either fail or suggest something (at worst the only suggestion would be EOF).
This rule applies both to the whole autocompletion, but also to each of its paths. Every single path will either fail or suggest.
And this assumption is really useful for error recovery: we can put "breakpoints" at the beginning of important rules and once they finish, check if there is a new suggestion. If there isn't we can try to recover.
But what if the grammar doesn't have an EOF? Then there may be situations when the autocompleter tries to recover unnecessarily. I don't think
it's worth handling because this situation only happens when you have consumed all the tokens, and therefore the recovery will fail quickly.
Implementing failure detection
The main idea is to compare the number of suggestions before and after starting every rule. This might look easy, but it can get tricky.
First problem: Saving the number of suggestions
I thought I could simply use the parserStack defined in the last post, but there is a problem: The autocompleter doesn't traverse transitions immediately.
Instead it pushes them into a stack (the main stack, not the parserStack) and finally traverses the last element of the stack. This means
it's a depth first search, which is perfect, BUT it means that in between the time it adds it into the stack and when it actualy executes it, other
transitions or rules could get executed and add suggestions, invalidating the stored number.
I know this is a bit confusing, so let's see an example:
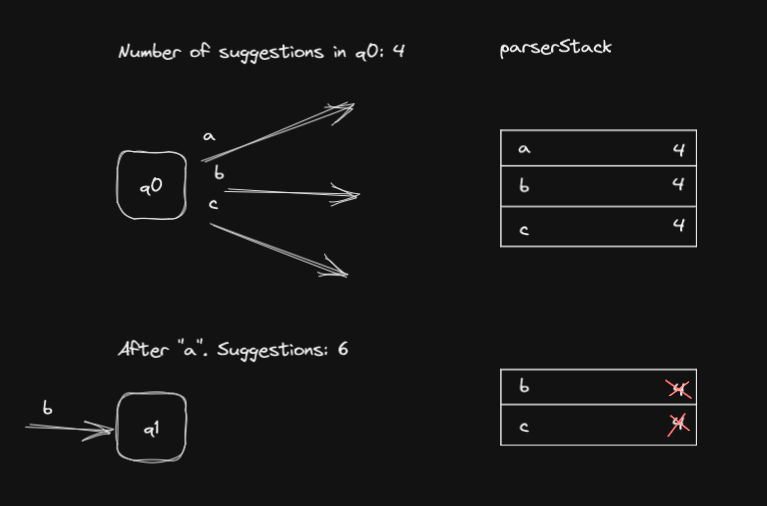
In this example q0 has three transitions. When it reaches that state there are 4 suggestions so it adds the 3 transitions to the parserStack annotating
that number. Then it executes the transition a, which leads towards a path that finds two suggestions. Then the machine tries the transition b, but
the "4" it had stored in parserStack is not longer valid. b could fail and the machine would think it hadn't due to the suggestions added by the path a.
This is a bit of nitpicking. Usually we want to track rule states which (I think) always have a single transition. But it's better to be safe, plus this could allow using some algorithm to optimize ATNs and reduce the number of epsilon transitions without worrying about corner cases. That said, if this problem is not enough for you, don't worry, there's another one.
Second problem: Failure 🧨💥
The idea was to store the number of suggestions in the parserStack and then compare it when the rule finishes, but... well, if it fails the rule never
finishes. It never reaches a RuleStopState where we can check if the number has changed. Oopsie! 🙈
The solution: Using the regular stack
To solve both problems we are going to have to modify the stack. Not the parserStack, but the regular one (the one we used to remove the recursion).
When we enter a rule we won't remove it from the stack and instead we will annotate the current number of suggestions (to be more precise we will pop it and then repush it with an extra parameter).
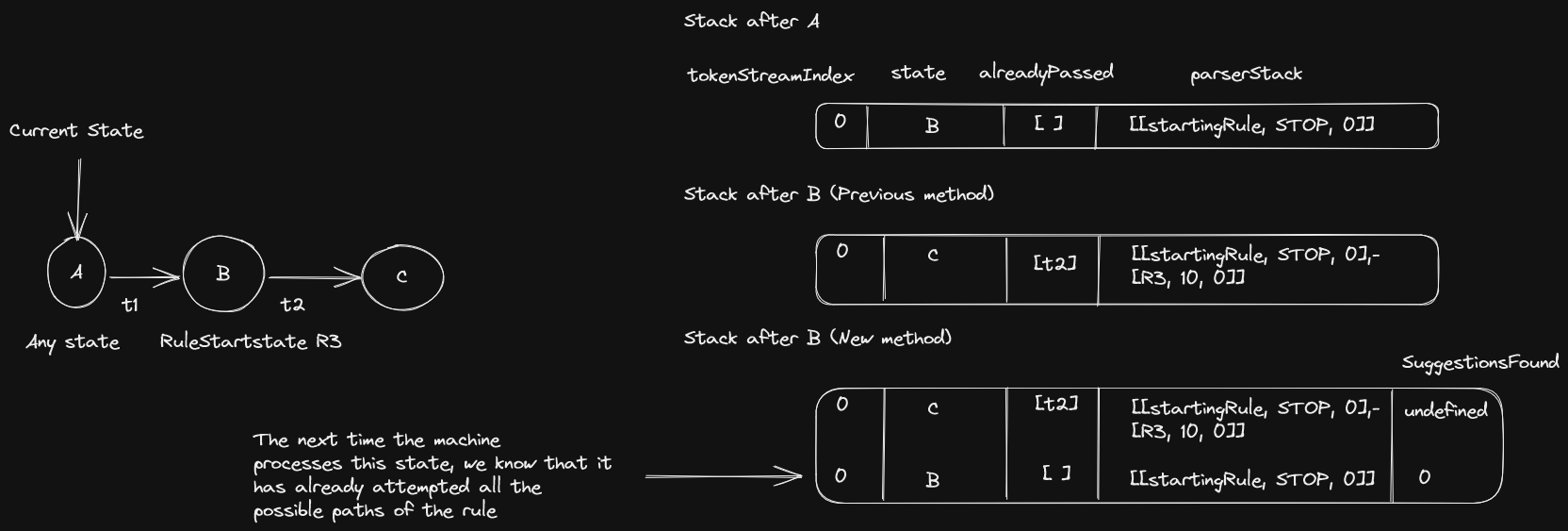
I know it's a bit weird to store an undefined in the states that aren't rules, but still this solution is perfect for three reasons:
- Even if the paths after the state
cfails, we know that the machine will continue processing the stack and go back to theBentry. - We know for sure that once the machine enters the
Bentry a second time, it has already traversed all possible paths inside that rule AND that it hasn't traversed any other path.
- Since this is a blog about parsing, this is quite similar to a visitor:
visitRule(ctx) { const before = suggestions.length; this.visit(ctx.children); const after = suggestions.legth; if (before === after) recover(); }
- Since this is a blog about parsing, this is quite similar to a visitor:
- If five subpaths inside the same rule fail, it will only trigger the recovery once because we are only checking if it should recover when we re-enter the
rule entry.
- This is really important since, as I mentioned before, the machine traverses a lot of paths that fail (and that's OK), but we don't want to trigger one recovery for every single one of them.
To implement this, first we need a list with the recovery rules. I'll assume they are in the "options" attribute and pass it to the process function:
autocomplete(input) {
//...
const suggestions = process(tokenList, stack, this._parser, this.options);
}
//...
function process(tokens, stack, Parser, options) {
Then we need to add the code that repushes the stack entry, but only if it's a rule transition. I'll add this code when it enter an epsilon transition
(since RuleTransition is epsilon).
function process(tokens, stack, Parser, options, atn) {
// ...
for (let i = state.transitions.length - 1; i >= 0; i--) {
if (it.isEpsilon && !alreadyPassed.includes(it.target.stateNumber)) {
//...
if (limitNextState && it.target !== limitNextState) continue;
let recoveryRules = options?.recovery ? options.recovery.filter(x => x.ifInRule === it.ruleIndex) : [];
if (it instanceof RuleTransition && recoveryRules.length > 0) {
// We are going to enter a rule that has a recovery rule.
// So we repush the current state but adding the number of suggestions and then add
// the next state
stack.push([tokenStreamIndex, state, alreadyPassed, parserStack,
{suggestions: suggestions.length, recoveryRules} // <-- This is the new object added to the stack
);
}
// This was the normal push that we were already doing
stack.push([tokenStreamIndex, it.target,
it instanceof RuleTransition || state instanceof RuleStopState ?
[]:[it.target.stateNumber, ...alreadyPassed], newParserStack]);
I made two minor unnecessary pre-optimizations. First I only repush the rule entry if the rule has a recovery rule defined. This way it avoids reentering every single rule just to check if there is a recovery rule defined and exit when there is not. The second one is that I also save the list of recovery rules that can trigger with that rule so that I don't have to look for them again later.
Now we have to access this new parameter of the stack:
function process(tokens, stack, Parser, options, atn) {
const suggestions = [];
while(stack.length !== 0) {
let [tokenStreamIndex, state, alreadyPassed, parserStack, recoveryData] = stack.pop();
And finally, check if the number of suggestions has changed.
function process(tokens, stack, Parser, options, atn) {
const suggestions = [];
while(stack.length !== 0) {
let [tokenStreamIndex, state, alreadyPassed, parserStack, recoveryData] = stack.pop();
let limitNextState = null;
if (recoveryData !== undefined) {
// If the number doesn't match, it means the rule hasn't failed. And since the rule has
// already being traversed, there's no need to do it again (hence the 'continue')
if (suggestions.length !== recoveryData.suggestions) continue;
let rule = recoveryData.recoveryRules[0];
onFail(stack, tokens, parserStack, tokenStreamIndex, atn, rule);
// onFail already adds a new entry to the stack, there is no need to traverse the
// current rule again
continue;
}
To keep it simple, I assumed that we only attempt the first recovery rule that matches the criteria. Trying multiple would require also detecting if the last recover failed, which is theoretically possible by re-adding the rule entry a third time and saving which was the last attempted recovery rule. I'll try to do it later if I have time.
But ignoring that for now, all that's left is to define onFail. This function looks for the recovery token and if it finds it, it adds a new state to the stack:
function onFail(stack, tokens, parserStack, tokenStreamIndex, atn, rule) {
const {andFindToken, thenGoToRule, skipOne} = rule;
// tokenStreamIndex + 1 to avoid it from recovering in the same token, which
// would be confusing . If you have let = = let a = b the rule starts in the
// first 'let' so it wouldn't make any sense to try to recover by entering the
// same rule at the same point again (it would obviously fail again)
for (let i = tokenStreamIndex + 1; i < tokens.length; i++) {
if (tokens[i].type === andFindToken) {
stack.push([skipOne ? i + 1 : i, atn.ruleToStartState[thenGoToRule], [],
// We add the current rule to the parser stack as if it had been entered through a RuleStartTransition
parserStack]);
return;
}
The skipOne is because in some rules it makes sense to skip the token whereas in others it doesn't. For example if your rule is "when you find a ;, go
to this rule" you probably want to skip that ;. But if the rule is "if you find let go to the rule variableDefinition", you probably won't, since let will
be the first token consumed by variableDefinition.
To test all this I made another extension to the testing framework:
const recoveryBase = givenGrammar(`
expression: assignment | simpleExpression;
assignment: (VAR | LET) ID EQUAL simpleExpression;
simpleExpression
: simpleExpression (PLUS | MINUS) simpleExpression
| simpleExpression (MULTIPLY | DIVIDE) simpleExpression
| variableRef
| functionRef
;
variableRef: ID;
functionRef: ID OPEN_PAR CLOSE_PAR;
VAR: [vV] [aA] [rR];
LET: [lL] [eE] [tT];
PLUS: '+';
MINUS: '-';
MULTIPLY: '*';
DIVIDE: '/';
EQUAL: '=';
OPEN_PAR: '(';
CLOSE_PAR: ')';
ID: [a-zA-Z] [a-zA-Z0-9_]*;
WS: [ \\n\\r\\t] -> channel(HIDDEN);
`);
it("test basic recovery", async () => {
recoveryBase.withRecovery((parser) => {
const foo = {ifInRule: parser.RULE_assignment, andFindToken: parser.VAR, thenGoToRule: parser.RULE_assignment};
return [foo];
});
await recoveryBase.whenInput("let = = var a =").thenExpect("ID");
await recoveryBase.whenInput("let a = b").thenExpect(["PLUS", "MINUS", "MULTIPLY", "DIVIDE", "OPEN_PAR"]);
await recoveryBase.whenInput("let = = var a = b").thenExpect(["PLUS", "MINUS", "MULTIPLY", "DIVIDE", "OPEN_PAR"]);
});
Voilah! It works. That said, this system is not perfect and might still attempt too many recoveries. I have already found and fixed a couple of things, but this post is getting too long, so I'll leave the improvements for the next one.