- Published on
Building an Autocomplete Library for ANTLR4 Part 5 - Improving the error recovery
In the last post I developed a proof of concept for defining recovery rules. As the name implies, it's a way of telling the ATN how to recover from specific conditions. But as they say, all that glitters is not gold, and the approach I followed has some flaws.
Measuring attempts
For some reason today I feel the need to keep making quotes, so lets say: What doesn’t get measured doesn’t get managed (Does using this quote qualify me as a productivity guru? I could easily talk about Notion 😈).
In order to improve the recovery we need a way of knowing how many recoveries it's actually doing. So I made a debug mode.
I created a small class DebugStats that contains the number of times that a rule attempted to recover, which doesn't mean
that it did, since the recovery could fail too. It's as simple as making the onFail method call options.debugStats.recovery(rule);
And here I discovered something odd. I stole grabbed the Java grammar in the antlr4-grammars repository and tried the following:
const grammar = givenFiles("JavaLexer.g4", "JavaParser.g4").withRecovery((parser) => {
const r = {
ifInRule: parser.RULE_blockStatement,
andFindToken: parser.SEMI,
thenGoToRule: parser.RULE_blockStatement,
skipOne: true};
return [r];
});
let debugStats = await grammar.whenInput(`class HelloWorld {
${`public static void main(String[] args) {
System.out.println("foo");
}\n`.repeat(200)}
public static void main(String[] args) {
// It's missing a ) and yet it advances to the next statement and autocompletes it correctly.
System.out.println("foo";
System.out.println("foo"
`).thenExpect(expected);
console.log(debugStats.toString());
This example defines 200 methods CORRECTLY, then starts one more method with a syntactically incorrect statement, and finally adds a unfinished statement, which is where the cursor is. The test passes and gives the expected result, but how many times it should have tried to recover? Obviously one, in the only syntactically incorrect spot, right? Well...
{"78-84-78":{"rule":{"ifInRule":78,"nested":true,"andFindToken":84,"thenGoToRule":78,"skipOne":true},"attempts":201}}
201 FREAKING TIMES? <lie>WOW That was unexpected</lie> So what's happening? And is it a coincidence that there are 200 hundred more methods than it should and I defined precisely 200 hundred syntactically valid methods before the one that fails? Is it a conspiracy?🛸🛸🛸🛸
Let's take a look at where the rule blockStatement is used in the grammar:
block
: '{' blockStatement* '}'
;
The key to why it's trying to recover so many times is in the asterisk, which you should already know that means "match 0 or more blockStatement. The thing is,
once it ends one blockStatement it has two choices: Enter the same rule again, or go to the }. So which one it chooses? Both. As I have already mentioned
a hundred times in these posts, we are traversing the ATN exhaustively meaning it checks boths options.
So what happens is that it tries to enter the rule again, finds the }, crashes and attempts to recover. And now you might be thinking: Shouldn't it had
a cascading effect? The first error recovery would also fail in the second method definition, triggering another recovery. So (without making the real
math) the number of attempted recoveries should be something like 200! (The main path fails 201 times, the first error recovery fails 200 times, the second one 199...
The answer to why this isn't happening is that the rule isn't well defined 😭, so each recovery fails immediately (except the last one). This might have saved us from a million recovery attempts in this specific situation, but it's still a bug that we have to fix.

Let's handle the problems one by one.
Avoiding entering rules that clearly fail
If the problem is it's entering a rule that obviously fail, the solution is to not enter it (this reminds me of: "feeling sad? Just stop feeling sad"). Before entering a rule we'll check if the next token is inside it's FIRST set. The FIRST is the set of tokens that can appear as the first symbol of a rule. If the first token already doesn't match, there's no point in entering.
I'll calculate the FIRST at the beginning of the autocompletion and cache it. Luckily it's quite simple, we just need to call the autocompleter itself starting at the rule we want to calculate. We will pass it a single token: The caret itself.
autocomplete(input) {
this.options.__cache = {};
for (const rule of parser.atn.ruleToStartState) {
this.options.__cache[rule.ruleIndex] = process([caret],
[[0, parser.atn.ruleToStartState[rule.ruleIndex],
[],
[[rule.ruleIndex, STOP, 0]]]],
// To keep the parserStack of the suggestions consistent, the cache stores Suggestions, not just the token
this._parser, {recovery: [], debugStats: this.options.debugStats, __cache: null}, parser.atn,);
}
A small detail here is that process return a list of Suggestions, not a list of token indexes. I won't do a map to get only the indexes for a reason:
Since we are going to cache the values we can also use those suggestions if we enter a rule and immediately find a caret. And to build that
suggestion we need to fully build the context.
For example imagine that we have a rule foo: var B. The FIRST of var is the same as FIRST of foo. But if
we want to build the final suggestion the parser stack must reflect that it comes from foo -> var and not just foo nor var.
With the FIRST cached, we can add the condition "If it's a RuleTransition and nextToken isn't in FIRST, skip it".
function process(tokens, stack, Parser, options, atn) {
//...
if (it.isEpsilon && !alreadyPassed.includes(it.target.stateNumber)) {
if (it instanceof PrecedencePredicateTransition && it.precedence < parserStack[parserStack.length - 1][2])
continue;
// This below is the new code
const nextToken = tokens[tokenStreamIndex];
if (it instanceof RuleTransition && options.__cache) {
if (nextToken === caret) {
// Use the cached suggestions instead of letting the machine run
options.__cache[it.target.ruleIndex]?
.forEach(s => suggestions.push(new Suggestion(s.token,
[...(parserStack.map(x => x[0])), ...(s.ctxt[0])])));
continue;
} else if (!options.__cache[it.target.ruleIndex].map(s => s.token).includes(nextToken.type))
continue;
}
Optional - Building the suggestion context
The building of the ssuggestion context can be a bit confusing, so let's review the basics. Usually the context is built from the parserStack, which as the name implies knows the list of nested rules at a specific moment. It's implemented as a list of integers,
each one identifying a rule.
So imagine a suggestion has the context [1,2,3,4,5]. If this suggestion had been cached, a part of that context would come from the
the current status of the machine, let's say [1,2,3], this would be the parserStack.map(x => x[0]) (remember that the parserStack
contains more information besides the index of the rule, that's why we map it to extract only the index).
The cached rule will have the remaining of the context. Let's use the previous example and say we have foo: var B. Here foo would have
id 4 and var 4. So the context is built by fusing the [1,2,3] and the [4,5].
So why the [0] in ...(s.ctxt[0])? Because a suggestion can have multiple contexts. When it's found it's set with just one. But at the end
of the autocompletion the duplicated suggestions are merged into one with multiple contexts. And why do I assume that there is only one?
Honestly, because it's easy and probably happens most of the time.
In theory it could have multiple contexts and I should build the combination of contexts, but I need to do some compromises to avoid becoming insane.
And voilah! Running the previous test returns:
{"78-84-78":{"rule":{"ifInRule":78,"nested":true,"andFindToken":84,"thenGoToRule":78,"skipOne":true},"attempts":1}}
Finally it only tries to recover once!
Oopsie: Recoveries don't really work
You've been lied (or as we would say in Spain: "Emosido engañado"). Yes, the recovery works in the nitpicked examples that I chose, but
there's an easy way to break it, And the main culprit is that the thenGoToRule doesn't really fit with repetitions.
Let's go back to the example:
// antlr4 rule
block
: '{' blockStatement* '}'
;
// Recovery rule
{
ifInRule: parser.RULE_blockStatement,
andFindToken: parser.SEMI,
thenGoToRule: parser.RULE_blockStatement,
skipOne: true
}
The previous recovery rule says: "If you are in a block statement and it fails, find the closest semicolon, skip it and start a new block statement". This is fine as long as the last the syntax error isn't in the last blockStatement. For example:
public static void main(String[] args) {
System.out.println);
}
When it tries to recover it will find the ;, skip it and start another blockStatement at }. The thing is, } isn't a valid beginning, so it will
fail again. And this time it won't recover.
So the answer isn't saying "go to this rule" but instead, "end the current rule and keep going as if everything had gone well".
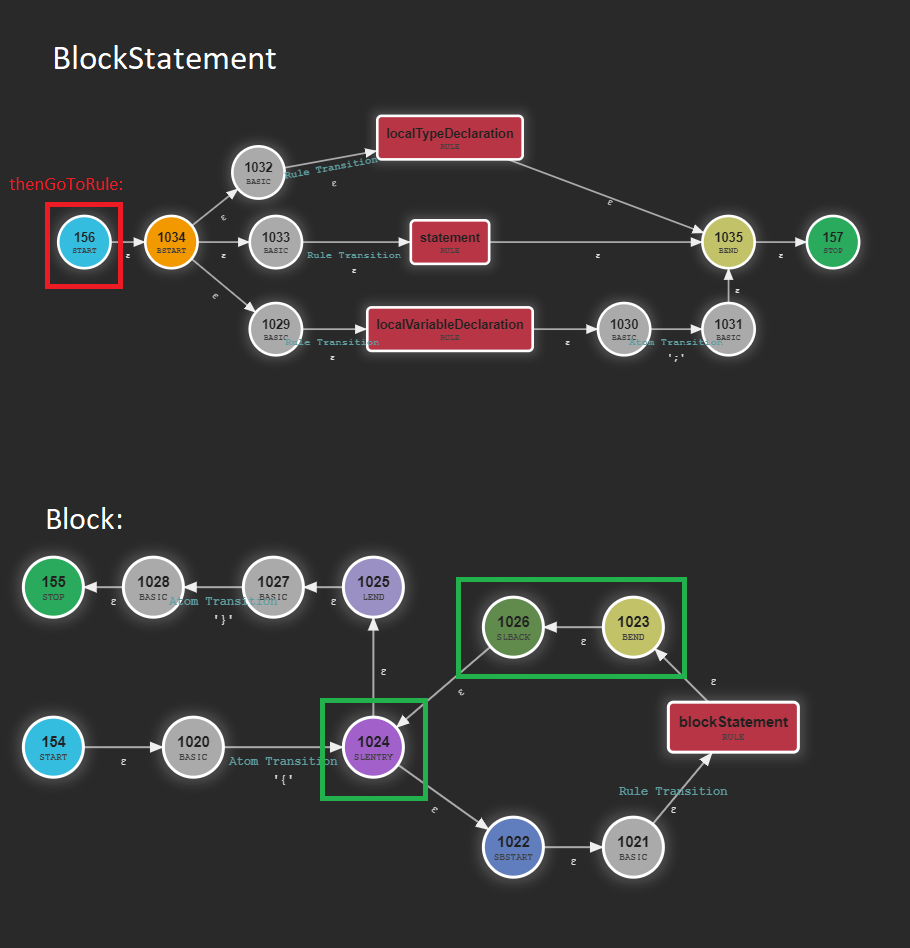
In this case when a blockStatement fails, it should go to one of the states marked in green (since they are all epsilon it doesn't really matter, but
the 1023 makes more sense). So rather than a goToRule it should be a finishTheRule.
With the perspective of time (I actually implemented this several months ago, then reimplemented a refactor just for the blog... I'm a bit of a mess), I can
see clearly that it makes so much more sense. I'm open for new modes of recovery, so for know I will keep a thenFinishRule: true in case in the future there
are other modes.
The thing is, accessing the followState here isn't as intuitive and direct as it sounds. Because by the time we execute the onFail we have
"backtracked" (removed from the stack) all the states inside the rule, and we are in the state BEFORE entering the rule.
So since we can't get the followState from the stack, fail has a new argument: currentState, which is simply the current state of
the machine. It assumes this state has a single transition which is a RuleTransition.
function onFail(stack, tokens, parserStack,
tokenStreamIndex, atn, rule, options, currentState) {
const {andFindToken, thenGoToRule, skipOne, thenFinishRule} = rule;
for (let i = tokenStreamIndex + 1; i < tokens.length; i++) {
if (tokens[i].type === andFindToken) {
options.debugStats.recovery(rule);
if (thenFinishRule) {
stack.push([skipOne ? i + 1 : i, currentState.transitions[0].followState, [],
parserStack]);
}
return;
}
}
}
And with that:
it("test recovery with repetition", async () => {
const grammar = givenFiles("JavaLexer.g4", "JavaParser.g4").withRecovery((parser) => {
return [{
ifInRule: parser.RULE_blockStatement,
andFindToken: parser.SEMI,
thenFinishRule: true,
skipOne: true}];
});
await grammar.whenInput(`class HelloWorld {
public static void main(String[] args) {
System.out.println("foo";
}
public static void main
`).thenExpect(["("]);
});
Imagining an expansion
This two improvements finish the development of my error recovery PoC. I'm pretty sure that it's still full of holes that would appear as fast as light if someone uses it seriously. But I don't have enough focus time to keep working on it, and I also want to work on other (probably smaller) projects.
My life is splitting in too many directions, and I dedicate so little time to this project each week that I spent most of it trying to remember what I did the previous one.
Still, let's dream a little. Notice that this are random thoughts of a slightly tired person. So take them with a grain of salt.
Recovering from multiple recovery tokens
Imagine the "JS-like" grammar that I used in the previous post. You can define a rule to recover from let foo = ; let xz = 4, but
not for let foo = ; potato; let xz = 3.
The algorithm attempts to recover at the first recovery token, but maybe recovering there fails and it wouldn't have had it recovered from the second or other recovery token. Of course this would be detrimental for performance, but maybe worth for some specific rules.
In order to avoid some performance issues you could establish a token limit, so that it stops after 1000 tokens, or 3 recovery attempts.
Recovery caching
Since the algorithm of the autocompleter traverses all the possible paths and the recovery rules have the same recovery tokens, it's possible that multiple paths fail and recover at the same point.
Maybe we could cache something like: {tokenIndexStream, recoveryRule, currentState} = Result. I'm not sure if it would be worth.
Guessing recovery rules automatically
In an attempt to make defining the recovery rules easier for the library clients, what if you didn't even need to put a recovery rule? If you could just say: "Recover from the rule expression" and it would just work.
Maybe it could be done with a combination of calculating the LAST set of every rule (the set of possible last tokens of a rule). For example if you had the typical definition: (VAR | LET) id EQ expr SEMI; it could automatically know that SEMI is always the last token.
This could be dangerous in cases where a token that can be the last token is also used in another position that isn't the last one. Since the autocompleter could recover before it has really finished the rule. But this is also a problem that the human has to take into account, so we could even detect it and show a warning. Plus if we combined this with recovering for multiple rules it would always recover correctly (potentially at a huge performance cost).
The end
If you are interested in seeing the full code, you can find the github repository right here: https://github.com/DanielBV/antlr4-shulk. It's far away from being production ready and I highly doubt I'll have the time to achieve it. But I think the experiment was worth it plus I learnt a lot from the ANTLR4 internals. I hope you enjoyed it too.