- Published on
Building an Autocomplete Library for ANTLR4 Part 1 - Introduction
As a programmer I use autocompletion on a daily basis. It helps me type faster and refreshes my memory with the names of previous variables and methods. So when we added autocompletion to an editor in my job, I couldn't help but wonder how it actually works.
The answer is not as straightforward as I thought. The first step to guess what the user will write is to understand what he has already written. Therefore, autocompletion is closely related to parsing, but there are a lot of parsers and parsing algorithms, each one with its own quirks.
Before we enter into parsing, a small disclaimer: I'm going to focus on autocompletion of formal languages. I won't enter into topics like machine learning or statistical models. To be more specific, this is going to be about ANTLR4, which is one of the most widely used parser generators.
In this series of posts I will develop a library that will have a lot in common with already existing libraries like antlr4-c3. And
in the process, we'll catch a glimpse of the inner workings of both antlr4-c3 and ANTLR4.
Parsing basics
For a computer, an expression like 3 + 4 is just text. You might unconciously assume that it's the sum of two numbers, but for a computer
it's nothing more than a series of characters. That's when parsing comes in. Parsing is the process of analyzing a string and transforming
it into a structure that the computer can understand. This structure is often a tree.
For example, for 3 * 5 + 4 a parser could generate a tree like:
+
/ \
* 4
/ \
3 5
A program could easily traverse this tree and calculate the final result. There is a multitude of parsing algorithms and libraries
but the most common ones are divided in two phases: Tokenization (done by the lexer) and parsing (done by the parser  ).
).
Tokenization is the process of breaking a string of text into individual words, called tokens. For example, in 12 + 34 the tokens would be
12, + and 34. Before tokenization, the computer saw 12 as two separate characters, but afterwards it understands that they
represent a single number. With the text divided into words, the parser analyzes them to determine the gramatical structure, resulting in a
parse tree.
The lexer and parser are usually built by defining a grammar and using a parser generator, like ANTLR4, to generate the code. A grammar for simple arithmetic could be:
expression:
expression ('*'|'/') expression // An expression is the multipication/division of two expressions
| expression ('+'|'-') expression // or the sum/subtraction of two expressions
| NUMBER; // or a number
NUMBER: [0-9]+; // A number is a sequence of one or more characters in between 0 and 9
ANTLR4 follows a naming convention which states that parser rules begin with lowercase and lexer rules with uppercase. Other parser generators might have slightly different syntaxes.
Autocompletion
Given the previous grammar, you can already see that if a user writes 3 + it should be easy to guess that the next token has to be a number.
However, there are two problems:
-
Parsing does not work well with incomplete text, and 99% of the time this will be the case.
Depending on the complexity of the rule, sometimes ANTLR4 can guess the next token and output error messages like
mismatched input '<EOF>' expecting <NUMBER>while other times it just throwsline 1:1 no viable alternative at input <EOF>.To add fuel to the fire, if it finds an error before the last token it'll stop and never reach that point. So even though it can be more or less intuitive that after
3 ++ 3 +there must be a number, the parser will crash when it sees the++. ANTLR4 can be configured to build incomplete parse trees, but they must be traversed carefully, since they are full of nulls andErrorNodes. -
The parser doesn't really tell you what could come next. If it parses correctly you get a parse tree. If it doesn't, you get an error that may or may not be useful and an inconsistent parse tree. You can't just ask the parser for suggestions.
One approach could be to build a visitor that suggest what goes after each node it traverses, and make it robust enough to handle incomplete nodes. This would work, but it must be done carefully and would also be really sensitive to the grammar's structure. If you refactor a rule it will explode.
The main reason I don't really like this approach is that it's too manual. It requires hardcoding rules that the parser should provide. And it does, in a way. Finally, it's time to talk about state machines.
State machines
Parsers are often implemented with a state machine. And what is a state machine? It's an abstract machine that is defined with states and transitions. When the machine receives an input it traverses its corresponding transition, changing the state. In parsers the tokens are the input, so given any state you can calculate what tokens the parser will accept next by looking at the transitions. To understand this better, let's see a simple example: Regular expressions.
Regex are implemented using state machines (I even made a whole 10 post series on that). You could even consider them parsers for regular languages. That's why they are a perfect example to illustrate in a simple way how the autocompletition library will work.
This is a state machine generated for the regex :

Imagine that the regex has already parsed the string "aaaaaaaa". If you follow the state machine, you'll see it's at the
state q2. Following the transitions from q2 you can guess that the next character has to be an a, b, or c. As I said
previously, you can't ask the parser what's the next token, but you CAN look at the state machine and calculate it.
The core idea of autocompletion in a parser is to simulate its state machine until the point we want to autocomplete (the caret) and then look at that state transitions to get the next possible tokens.
This example applies to regex, but it also works for parsers... with a catch. Most parsers don't have an explicit state machine. For example, this is how a rule in a LL(1) parser might look like:
expression() {
let localctx = new ExpressionContext(this, this._ctx, this.state);
this.enterRule(localctx, 0, ExprParser.RULE_expression);
try {
this.state = 14;
this._errHandler.sync(this);
switch(this._input.LA(1)) {
case ExprParser.VAR: // <---- Transition 1
case ExprParser.LET: // <---- Transition 2
this.enterOuterAlt(localctx, 1);
this.state = 12;
this.assignment(); // <---- State where transition 1 and 2 go
break;
case ExprParser.ID: // <---- Transition 3
this.enterOuterAlt(localctx, 2);
this.state = 13;
this.simpleExpression(0); // <---- State where transition 3 goes
break;
default:
throw new antlr4.error.NoViableAltException(this);
}
This code fragment was generated by ANTLR4. It might not look like a state machine,
but it is. this._input.LA(1) gets the lookahead, which is just the next token that the machine is going to consume.
Each of the options in the switch is a transition, and the this.assignment()/this.simpleExpression() are the
next states. You could say that this is like hardcoding a specific state machine in code, while the approach I followed in the
series of posts about Building A Regex Engine allowed defining and executing any NFA (a type of state machine).

If the state machine is implicit, making an autocompleter will be harder. Luckily, ANTLR4 does also have an explicit state machine
(hence the this.state). ANTLR4 uses an ALL(*) algorithm, which builds an ATN (Augmented Transition Network). I don't know
all the specific details of ATNs, but for this project let's say it's a state machine that allows substate machines. We'll see the
details later.
Optional - So what about the LL(1) snippet you mentioned literally 5 seconds ago?
When ANTLR4 analyses a grammar, it can detect if a rule is LL(1). If that's the case, it optimizes the generated parser so that it doesn't have to call the ATN. The rule is still added to the ATN, but (I guess) it's never called.
This is how a method of an ALL(*) rule looks:
simpleExpression(_p) {
if(_p===undefined) {
_p = 0;
}
const _parentctx = this._ctx;
const _parentState = this.state;
let localctx = new SimpleExpressionContext(this, this._ctx, _parentState);
let _prevctx = localctx;
const _startState = 4;
this.enterRecursionRule(localctx, 4, ExprParser.RULE_simpleExpression, _p);
var _la = 0; // Token type
try {
this.enterOuterAlt(localctx, 1);
this.state = 24;
this._errHandler.sync(this);
var la_ = this._interp.adaptivePredict(this._input,1,this._ctx); // <---------------------
switch(la_) {
case 1:
this.state = 22;
this.variableRef();
break;
case 2:
this.state = 23;
this.functionRef();
break;
}
To decide what's the next state it now calls var la_ = this._interp.adaptivePredict(this._input,1,this._ctx);.
And what is that this._interp? Exactly, an ATNSimulator:
this._interp = new antlr4.atn.ParserATNSimulator(this, atn, decisionsToDFA, sharedContextCache)
I don't fully know what magic adaptivePredict does. All I know (or more precisely, "all I can guess") is that it
determines which path to follow by looking ahead as many tokens as it needs.
In ANTLR4's ATN, every rule is a state machine. And calling a subrule is just calling the submachine. We can easily see these machines using the VSCode extension for ANTLR4. The rule
assignment: (VAR | LET) ID EQUAL simpleExpression;
generates the following ATN:
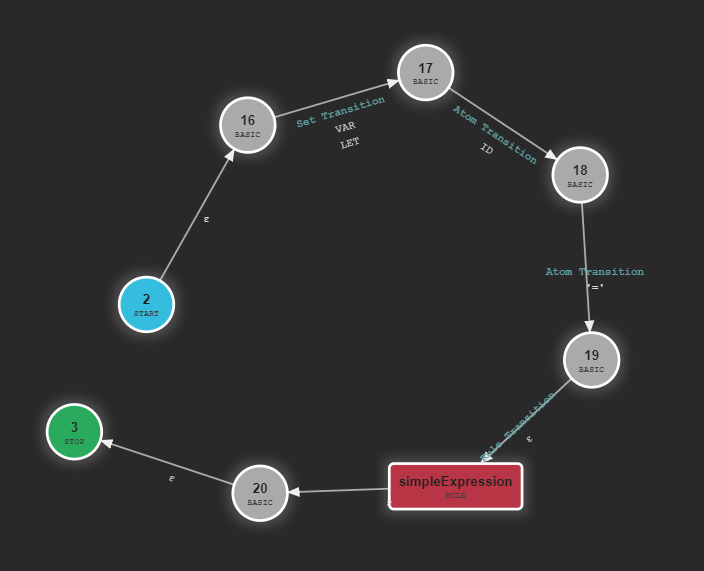
Surprisingly, we can see similarities with the regex example. After reading LET/VAR the parser will be in state
16, and from there it's easy to recognize that the next valid token must be an ID. And after an ID the next token is a
=.
In this case the ATN is linear because the rule is really simple. Alternatives and quantifiers make the machine more tangled,
so most ATNs won't look as nice as this one. And when I say "more tangled", I mean IMMEASURABLY MORE TANGLED.
I randomly scouted the grammars-v4 repo and generated the ATN graph of the rule simple_embedded_statement in CSharpParser.g4:

It's insane, and yet there is some beauty in the graph. That said, I'm sure there are a lot rules that generate even more complex networks.
A new adventure begins
All this extremely long post was just the general idea. In the following post(s?) I'll dwelve into the types of states and transitions and finally start writing some code.