- Published on
Adding capturing groups - Building a Regex Engine Part 4
In the last three posts we implemented a formal regex engine, but it's still really limited and not good enough for any real use. Today we'll add one of the most used features of modern engines, Capturing groups.
Till now, the engine always responded with "Yes, this string matches the regex" or "😂 Nice try", but capturing groups allow extracting the parts of
the string that matched a part of the regex. For example: .+@(.+)\.com can be used to extract the email domain of an email address
(let's ignore weird emails and email validation)
- Input string:
coolest-potato@gmail.com - Output
["gmail"]
Optional - Quick 'Did you know' about emails and regex
Never use regex for email validation. Instead you should delegate this problem to tried and trusted libraries. BUT... did you know there's a website (https://emailregex.com/) that shows a regex that (reportedly) works with 99.9% of emails? At the time of writing this post, that regex is:
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b
\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9]
(?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?
[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c
\x0e-\x7f])+)\])
(Added line breaks to make it more readable, if for some reason you want to copy the regex as it is just go to the website).
All I'm going to say is:

Understanding the details of capturing groups
By default every regex expression inside parenthesis is a capturing group. You can also make it a non-capturing group with the syntax (?:<expression>), this is often used
to wrap things in parenthesis without creating useless groups, for example ((?:a|b)+).
Most (maybe all?) regex engines use the capturing group 0 to output the whole text that matched the pattern. The following capturing groups are numbered from left to right.
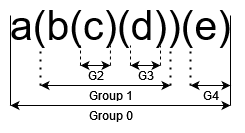
Alignment of parenthesis with vertical lines: -50 points.
Multiple groups can capture the same input, the most stupid example would be ((((a)))), where the same a would appear in 5 capturing groups (4 parentehsis + group 0).
But if a capturing group is transvered multiple times it only captures the last one. Let's see this with an example:
| Regex | (a+) |
| Input | aaaaa |
| Result | Group 0: aaaaa |
The group captures one or more a, so the result above is expected. But what happens if we take the + quantifier outside the capturing group?
| Regex | (a)+ |
| Input | aaaaa |
| Result | Group 0: aaaaa |
The group 1 only matches a single a, so even though the four a's are matched by that group, it only captures the last one. In implementations terms this means
every time we exit a group we'll override the old value.
Implementing capturing groups
To add this functionality we need to modify most parts of the engine:
- Parsing: If your parser didn't allow parenthesis or the non-capturing syntax, you'll have to add that. I won't cover this part.
- Building the AST: In the previous post we already had the nodes
RegexAlternativeandRegexbut they assumed it wasn't a capturing group. Now we'll add a variable to store whether it's capturing or not. - NFA model and building: The capturing groups have to be modeled in the NFA so we can use that info when we execute it.
- Engine execution: At every step of the execution we need to check if we are entering or exiting a capturing group and store the indexes of the captured substring.
Some code snippets only include the things that have changed. You can see the complete source code here. Let's begin.
Building the AST
This one is easy. Previously we had two main "compound" AST nodes: Regex (a single regex expression) and RegexAlternative. All we need to do is add an extra attribute
_capturing. We'll consider the root of the tree to be a group too (group 0), even though it doesn't have parenthesis. So the only case it isn't a capturing
group if it's an explicit non capturing group
aaa-> Regex(aaa, true)(aaa)-> Regex(aaa, true)(?:aaa)-> Regex(aaa,false)
A RegexAlternative contains multipe Regex. Even if the alternative is capturing, the inner regex are not:
(a|b)-> RegexAlternative([Regex("a", false), Regex("b", false)], true)
I think it would be simpler to merge Regex and RegexAlternative into a single AST node, but it's too late. If you can, don't overcomplicate the AST like I did.
Optional - A small reminder on AST
An AST (Abstract Syntaxt Tree) is a tree representation of a text. It's called abstract because it ignores some details of the text, and it might not be possible
to reconstruct exactly the same text from an AST. In the example above, aaa and (aaa) have the same AST, so given an AST you can't know whether the original text
had parenthesis or not.
There is no "standard AST". ASTs often have just enough information to fill the specific needs of the problem to solve. In this case I assume we have an ASTs like this one:
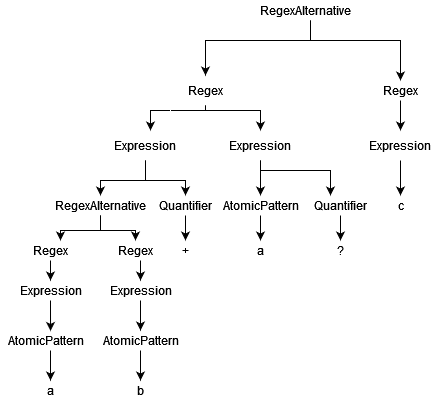
As I said in the previous post the AST has some unnecessary nodes, for example Expression is quite useless, since I could have added the quantifier to
a generic RegexNode class and then make all the other classes inherit from it. The code will assume this structure, but if you are going to implement your own engine
feel free to improve it all you want.
In my particular case due to how I made the AST builder it was easier to make groups capturing by default and then add a nonCapturing() method to set them as non-capturing.
class Regex {
constructor(subpatterns) {
this.subpatterns = subpatterns;
this._capturing = true;
}
isCapturingGroup() {
return this._capturing;
}
nonCapturing() {
this._capturing = false;
return this;
}
}
And the same for RegexAlternative.
Building the NFA
Previously the states of an NFA were just a label with some transitions. Now we need to store the information about groups somehow. These are the options I can think of:
- Tag the initial and ending states of a group.
- Tag the transitions. This is slightly more accurate because "TeChNiCaLlY" speaking 🥴 the groups would begin and end when you go through a transition, rather than when you enter or exit a state.
Both methods are only possible because Thompson's construction generates readable and intuitive NFAs, where it's clear where a group begins and ends.
For a NFA engine there's no much different between the two of them. I chose to tag the states because it was simpler. When I did a bit of research afterwards I discovered this topic get's much more interesting if you want to convert the NFA to DFA (Quick reminder: NFA = Non deterministic finite automata, DFA = Deterministic Finite Automata).
I'll talk more about this in the post about NFA vs DFA. As a quick spoiler, in a NFA it's easier to know which states are the beginning and ending of a capturing group. In formal DFA it's impossible because that information is lost during the conversion/minimization. To be able to keep the capturing groups you can't use the Powerset construction, instead you have to use an extended algorithm. The algorithms I'll mention in that post tag the transition instead of the state, since this allows to merge more states.
For the regex (a|b)*a(a|b):
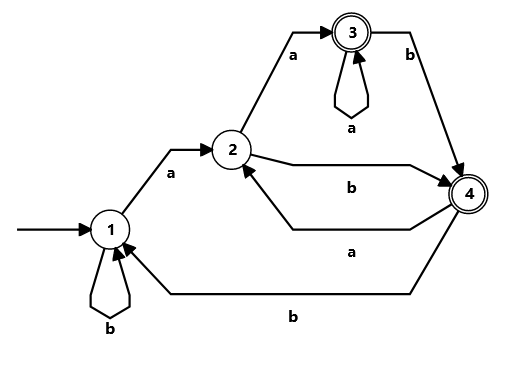
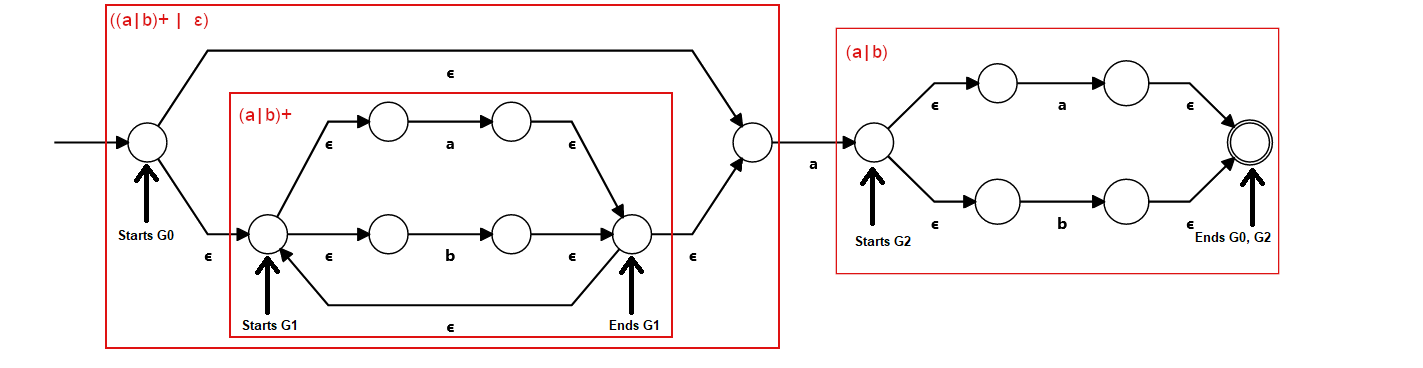
Are you able to see the states that start the groups 1 and 2 in the DFA? Because I definitively can't. Of course I'm cheating. The DFA is fully minimized with the Powerset construction. DFAs with capturing groups can't be minimized as much as formal DFAs, since in those you can merge more states without worrying about groups.
So as a recap: I'm going to tag the states, but if you intend to make a DFA engine it might be more useful to tag the transitions.

The model
First we are going to store the groups that start and end in each state. In most cases a state will start or end a single group, but there are some stupid corner cases line
(((a))). I'm also not sure if the states can both start and end groups at the same time, but I'll assume it's possible.
Each group will be represented with its name. This will also be useful to implement named capturing groups, but I'll talk about those later.
export class State {
constructor(name) {
this.name = name;
this.transitions = [];
this.startsGroups = [];
this.endsGroups = [];
}
addStartGroup(group) {
this.startsGroups.push(group);
}
addEndGroup(group) {
this.endsGroups.push(group);
}
//Methods previously defined
}
In EngineNFA I'll also add a method to add a group:
class EngineNFA {
// ... Previously defined Methods
addGroup(start, end, group) {
this.states[start].addStartGroup(group);
this.states[end].addEndGroup(group);
}
}
NFA Building
We just need to get the name of the group at the beginning of _singleRegexToNFA and apply the group at the end.
_singleRegexToNFA(regexAST) {
let nfa = null;
//...
// You have to define a concrete group name before visiting any subnode so that the order of the group
// numbers is ascending.
const groupName = regexAST.isCapturingGroup() ? this.newGroup() : null;
for (const c of regexAST.subpatterns) {
// A lot of code that was defined in the last post
}
// ...
// Be careful, 'if(groupName)' is not enough because group '0' would be false. I guess you instead you could
// convert the group to a string
if (groupName !== null) nfa.addGroup(nfa.initialState, nfa.endingStates[0], groupName);
return nfa;
}
_alternativeToNFA(alternativeAst) {
const groupName = alternativeAst.isCapturingGroup() ? this.newGroup() : null;
const nfa = this.nfaFactory();
// ... Other code
if (groupName !== null) nfa.addGroup(start, end, groupName);
return nfa;
}
It's simple, but we need to tie up a loose end. Both methods use appendNFA, a method that merges the initial state of the appended NFA with the "union state" (the state
where that NFA is appended). In the process a state is lost, what if there is a group there? All we need to do is move that information to the merge state, just like
we did with the transitions:
appendNFA(otherNfa, unionState) {
// ...
// Before we just added the transitions of the deleted state to the unionState
for (const [matcher, toTransition] of otherNfa.states[otherNfa.initialState].transitions)
this.addTransition(unionState, toTransition.name, matcher);
// Now we also move the groups
for (const group of otherNfa.states[otherNfa.initialState].startsGroups)
this.states[unionState].addStartGroup(group);
for (const group of otherNfa.states[otherNfa.initialState].endsGroups)
this.states[unionState].addEndGroup(group);
// ...
}
Finally we define the utilities for group numbering that we used in the previous methods:
class NFABuilder {
newGroup() {
const c = this.groupNumber;
this.groupNumber++;
return c;
}
resetGroupNumbers() {
this.groupNumber = 0;
}
// This method was already defined, we just add the call to 'resetGroupNumber'
regexToNFA(regexAST) {
this.resetStateNumbers();
this.resetGroupNumbers();
return this._regexToNFA(regexAST);
}
// ... Other methods
Executing the model
All we did until now was just so the NFA had the info about the capturing groups... now we need to do something with that info. And as always, it boils down to the
compute method in EngineNFA
In the second post of this series I gave the NFA a memory to avoid epsilon loops by storing visited epsilon transitions. We are going to use that same memory to keep
track of the capturing groups. We'll add a new variable GROUP_MATCHES and initialize it do an empty object (technically it's a map so I should have used new Map(), but
a plain object will also do the job).
Then every time we enter a new state we have to check if we just entered or exited any group. For that we'll call this.computeGroups. Also, before we always returned
either true if it matched or false otherwise. Now we'll change that to return memory if it matches or null if it doesn't.
class EngineNFA {
compute(string) {
const stack = [];
stack.push({i: 0, currentState: this.states[this.initialState], memory: {GROUP_MATCHES:{}, EPSILON_VISITED: []}}})
while (stack.length) {
const {currentState, i, memory} = stack.pop();
this.computeGroups(currentState, memory, i); // <-- This is new
if (this.endingStates.includes(currentState.name))
return memory;
// ...
}
return null;
}
// ... Other methods
}
It's important that we compute the groups before checking if we are in an ending state, otherwise the groups that end in the ending state (like group 0) would never be completed.
And in computeGroups we just check the startGroups and endGroups of the state. As a reminder, i is the position of the string where the NFA is at the moment,
which is the first letter that hasn't been consumed yet.
computeGroups(currentState, memory, i) {
for (const group of currentState.startsGroups) {
memory.GROUP_MATCHES[group] = [group, i, null];
}
for (const group of currentState.endsGroups) {
memory.GROUP_MATCHES[group][2] = i;
}
}
I store the groups in the format [group, start, end]. I know the group is redundant because it's also the key of the object but I like it this way (okay maybe I'm too lazy to
change it 😜).
Notice that each group is actually a right-open interval. When we run computeGroups we have already exited the group, so i points to the first non-consumed letter
after the group, not to the group's last letter. This won't be a problem, since the substring function is also right-open.
Making a decent output
With all these changes capturing groups already work! Still, the result isn't in a user-friendly format:
const nfa = new NFARegex("((?:a|b)+)(cd)");
const result = nfa.compute("bbaacd");
console.log(result); // {"GROUP_MATCHES":{"0":[0,0,6],"1":[1,0,4],"2":[2,4,6]},"EPSILON_VISITED":[]}
So let's improve that by calculating the substring that matched in each group:
class NFARegex {
compute(string) {
const memory = this.nfa.compute(string);
if (!memory) return null;
const result = {groups: {}};
for (const [group, start, end] of Object.values(memory.GROUP_MATCHES)) {
result.groups[group] = string.substring(start, end);
}
return result;
}
}
And now:
const nfa = new NFARegex("((?:a|b)+)(cd)");
const result = nfa.compute("bbaacd");
console.log(result); // {"groups":{"0":"bbaacd","1":"bbaa","2":"cd"}}
Much cleaner! You might be wondering why I used an object instead of a simple list. That's because most regex engines also allow to define the name of a capturing group.
Extra, extra! - Named groups

Named groups are a type of capturing groups where you can specify the name of the group. It follows the syntax (?<name>x), for example: (?<username>.+)@(?<domain>.+\.com).
This allows more expressive regexes.
With all the work we've already done, they are pretty easy to implement. First we need to parse that pattern and store it in the AST.
class RegexAlternative {
constructor(...alternatives) {
this.groupName = null; // <-- This is new
this._capturing = true;
this.alternatives = alternatives;
}
//...
}
class Regex {
constructor(subpatterns) {
this.subpatterns = subpatterns;
this.groupName = null; // <-- This is new
this._capturing = true;
}
//...
}
And then all we have to do is take that name into account in the nfa builder. So in _alternativeToNFA instead of
const groupName = alternativeAst.isCapturingGroup() ? this.newGroup() : null;
We'll have
const groupName = alternativeAst.isCapturingGroup() ? alternativeAst.groupName || this.newGroup() : null;
And the same for _singleRegexToNFA. Done! 😎
const nfa = new NFARegex("(?<lotsOfA>a+)(?<lotsOfB>b+)");
const result = nfa.compute("aaabb");
console.log(result); // {"groups":{"0":"aaabb","lotsOfA":"aaa","lotsOfB":"bb"}}
Just in case you should do a couple of checks to the names:
- What happens if there are duplicated group names? You could throw an error, keep the last one, autodestruct... so many choices.
- The engine shouldn't allow numbers as names, since it conflicts with regular capturing groups.
What's next
Capturing groups are a really important feature of modern regex, but the engine is still really flimsy. For example, while trying to test the code I tried to run
the regex I mentioned in the introduction (.+@(.+)\.com) and I was surprised when it failed. I didn't realize we haven't implemented character classes, like the
dot period, \w, or [a-z]. Don't worry, it can be fixed 🛠.
Season 1 - Building a Regex Engine (Completed)
- Introduction
- Implementing a NFA
- Creating a NFA from a regex
- Modern features - Part 1: Capturing groups
- Modern features - Part 2: Character classes and escape characters
- Modern features - Part 3: Anchors and multiline mode
- Finding multiple matches
- Modern features - Part 4: Atomic groups
- Modern features - Part 5: Backreferences
- NFA vs DFA